This DEMO introduces ItoTTS and ItoWave, a new generation of speech synthesis technology based on Ito stochastic differential equations.
Overview
ItoTTS and ItoWave are designed to solve the problem of generating speech from text. ItoTTS and ItoWave are based on linear Ito stochastic differential equation. Under conditional input, such as original text or original voice features (such as mel spectrogram), to employ the Wiener process as a drive to gradually subtract the excess signal from the noise signal, thereby generating realistic corresponding meaningful speech. This process is like Auguste Rodin carved out “the thinker” from the original natural stone. He uses carving techniques and methods to gradually remove the superfluous parts from the natural stone. Our method can deal with both important aspects in speech synthesis, namely text-to-speech (TTS) and vocoder, in the same framework, which we call ItoTTS and ItoWave, respectively. This same framework consists of two stochastic processes, which are pair solutions determined by the linear Ito stochastic differential equation and its corresponding reverse-time Ito stochastic differential equation, respectively. These two stochastic processes, especially the reverse stochastic process, can generate mel features under the condition of text input(ItoTTS); or generate corresponding waveform under the condition of mel spectrogram(ItoWave). The experimental results show that our MOS reaches the best in the world.
The key module: Score predictor
The most important module of our ItoTTS and ItoWave is a deep neural network for predicting the log density gradient (a.k.a. score) of speech data.
Mel spectrogram score prediction network structure in ItoTTS is shown in the following figure
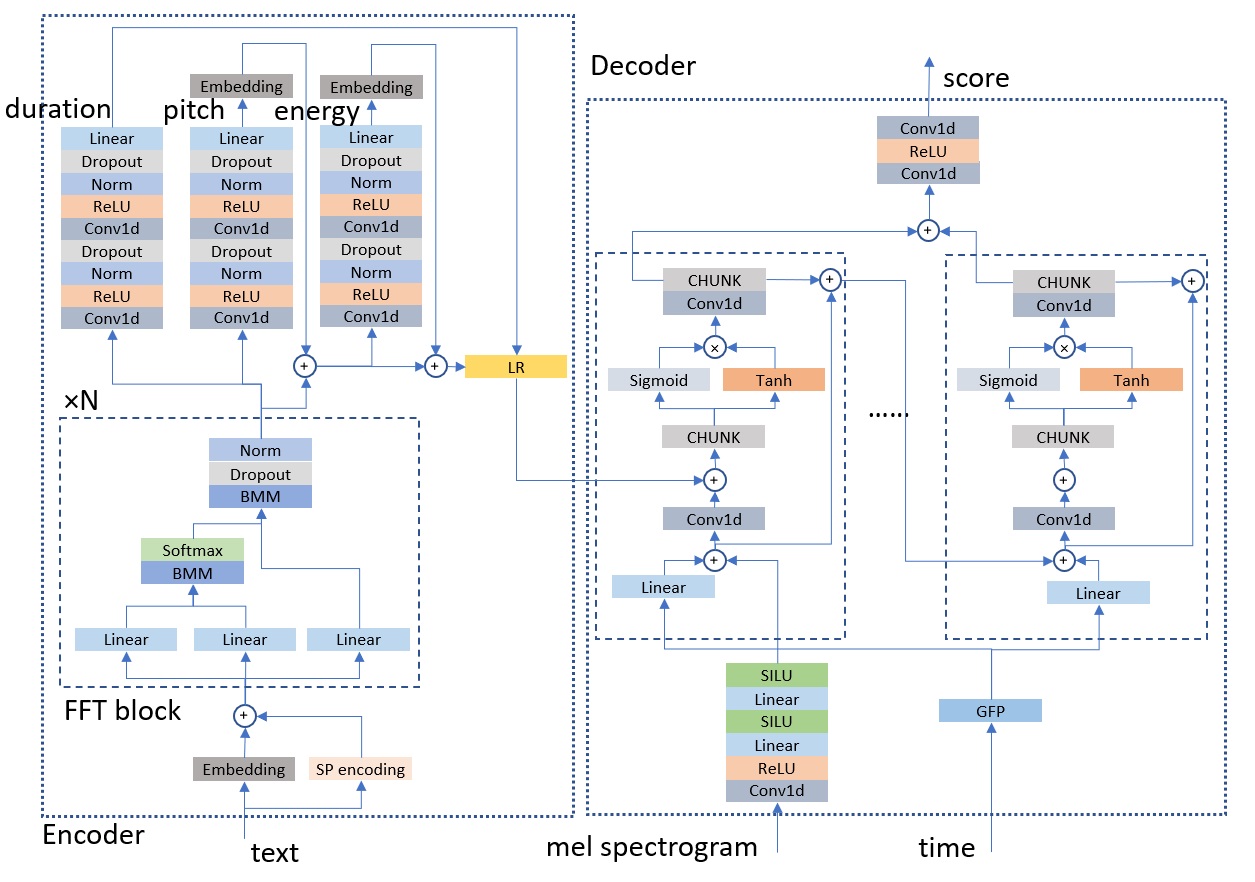
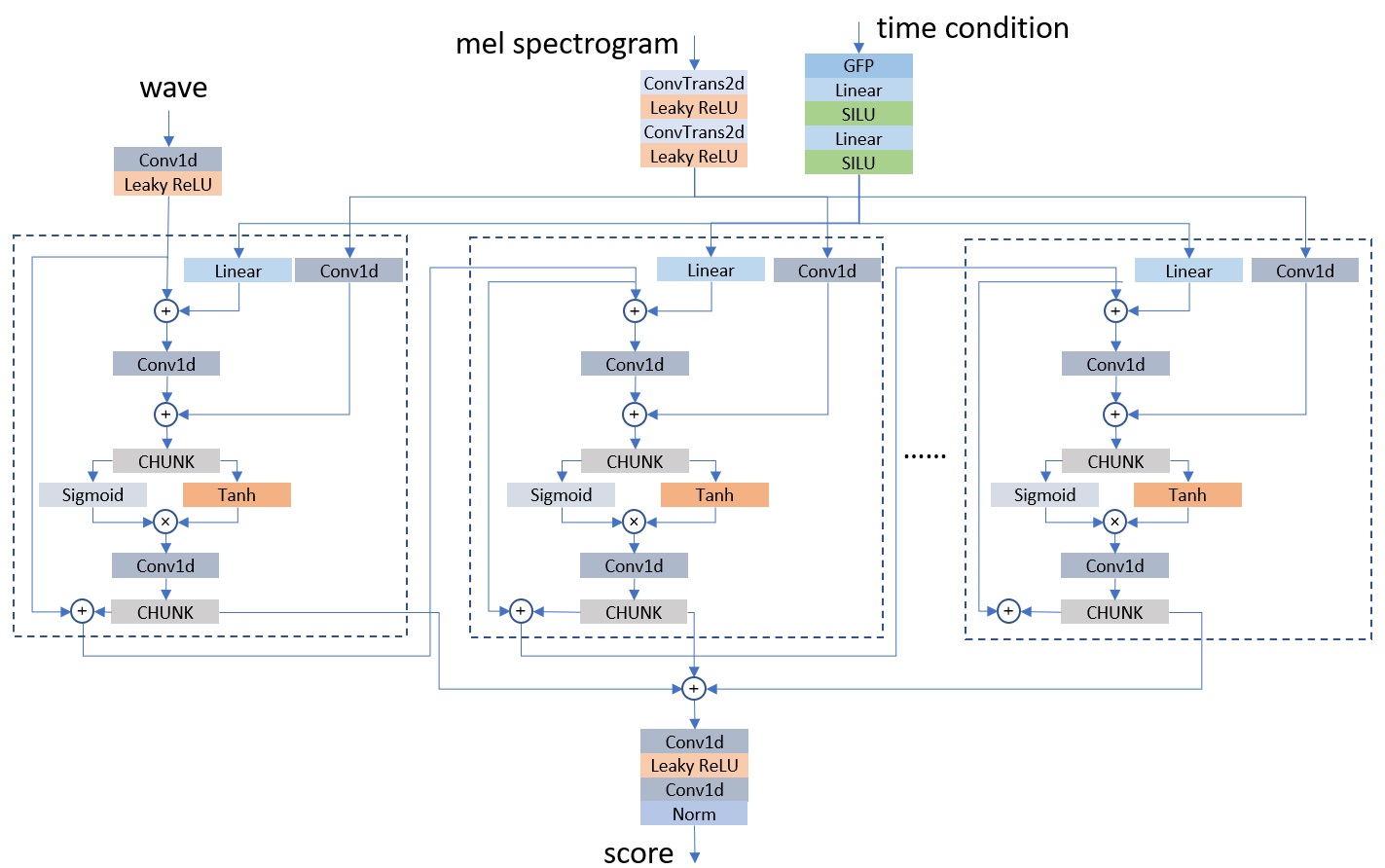
Wave score prediction network structure in ItoWave is is shown in the following figure
Audio samples
You can listen to some sound samples synthesized by ItoTTS and ItoWave.
Short samples
The corresponding texts are as follows:
-
but they proceeded in all seriousness, and would have shrunk from no outrage or atrocity in furtherance of their foolhardy enterprise.
-
three cars for press photographers, an official party bus for white house staff members and others, and two press buses.
-
a base station at a fixed location in dallas operated a radio network which linked together the lead car,
-
the lifting had been so complete in this case that there was no trace of the print on the rifle itself when it was examined by latona.
-
with the active cooperation of the responsible agencies and with the understanding of the people of the united states in their demands upon their president,
Comparison of synthetic effects between ItoTTS and other TTS systems
| Ground truth | FastSpeech 2 | Tacotron 2 | ItoTTS |
Synthesis effect comparison between ItoWave and other vocoder systems
| Ground truth | WaveNet | WaveGlow | DiffWave | WaveGrad | ItoWave |
Long samples
ItoTTS can synthesizes very long speech, e.g. one piece of news from “China Daily” about 7.12 Beijing Heavy Rain:
Beijing took multiple measures on Monday to cope with the heaviest rain to hit the capital this year. The downpours, along with strong winds, started on Sunday night and are forecast to last until Tuesday morning. From 6 pm on Sunday to 7 pm on Monday, an average of 100.4 millimeters of rain fell across the capital, according to the city’s meteorological bureau. However, by late Monday afternoon there was no deep surface water on major roads in urban areas, after city authorities activated pumping stations. Flood warnings were also issued for residents of high-risk areas. Kindergartens and primary and secondary schools in the city suspended classes on Monday and company employees were encouraged to work from home or alter their travel times.
| ItoTTS |
The diffusion generation
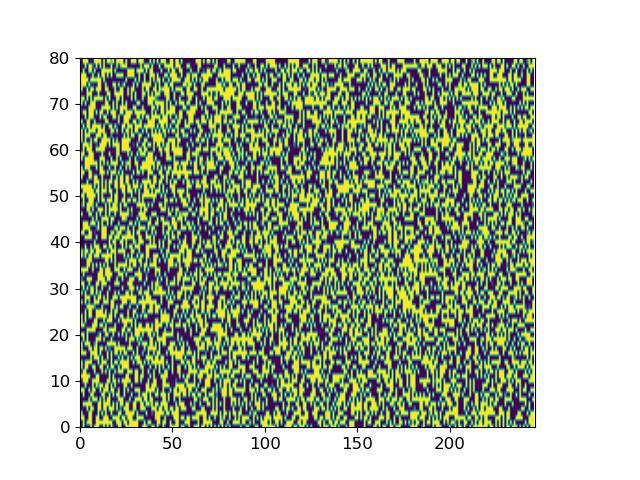
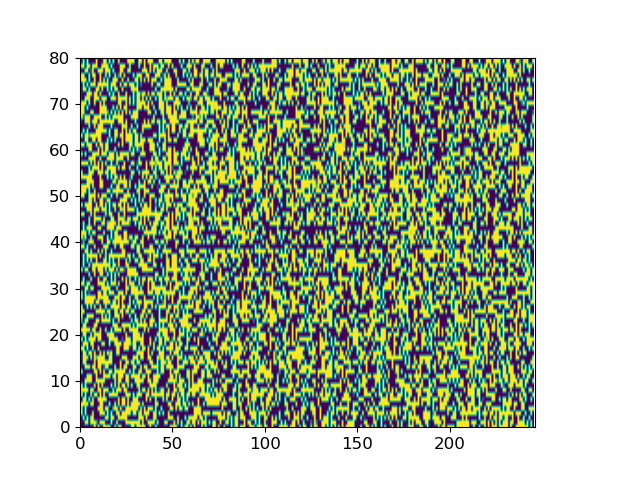
Here we give two examples of the diffusion process by which ItoTTS and ItoWave turn white noise into meaningful speech.
With “to be or not to be, this is a big problem” as the conditional input text, ItoTTS gradually generates the corresponding mel spectrogram from the Gaussian noise signal.
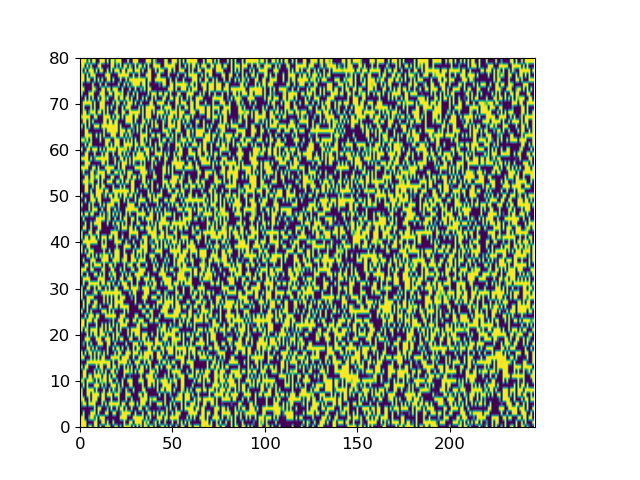
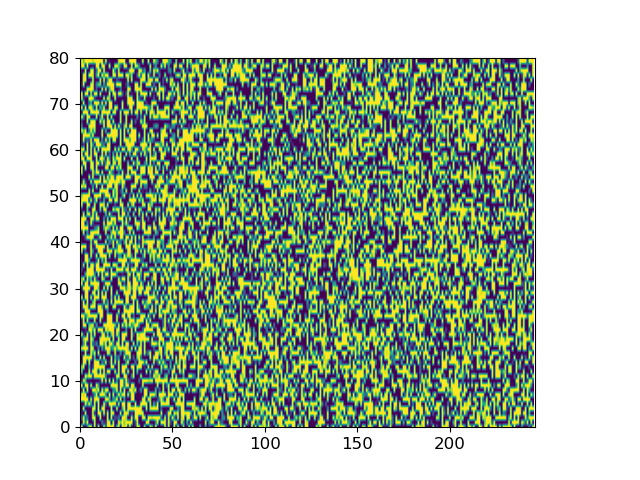
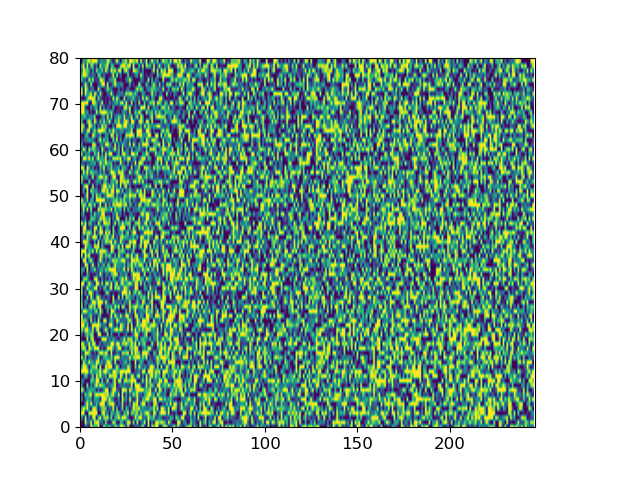
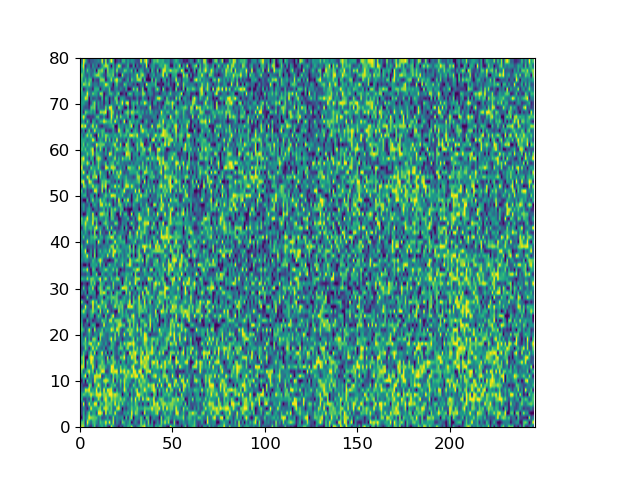
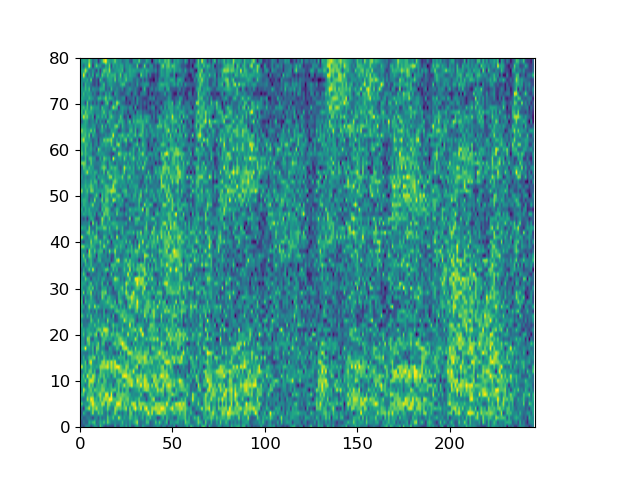
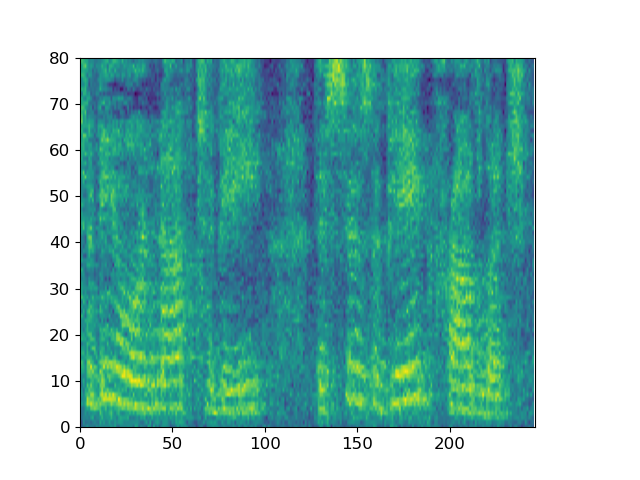
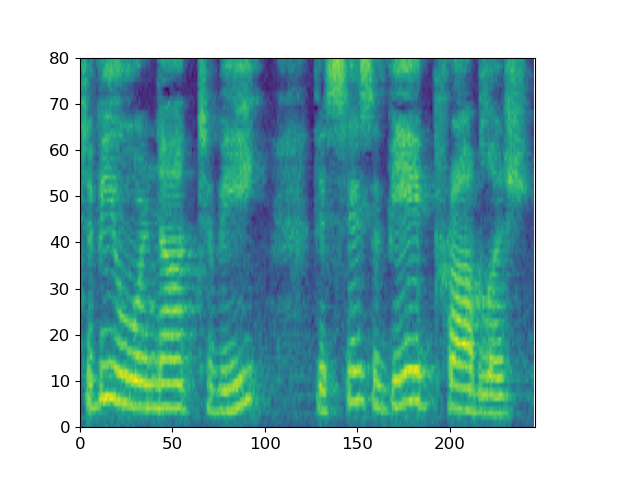
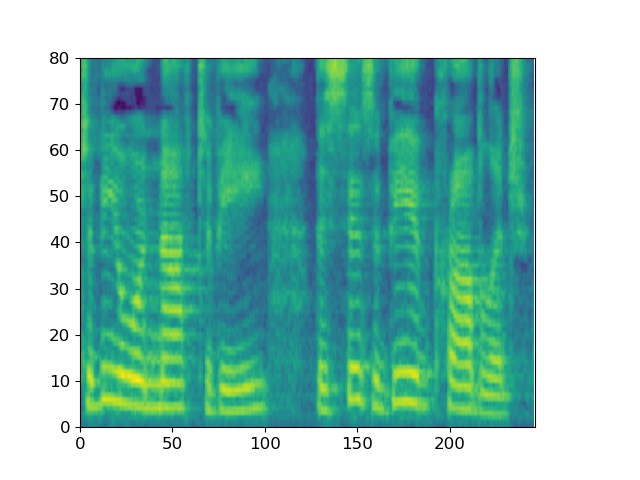
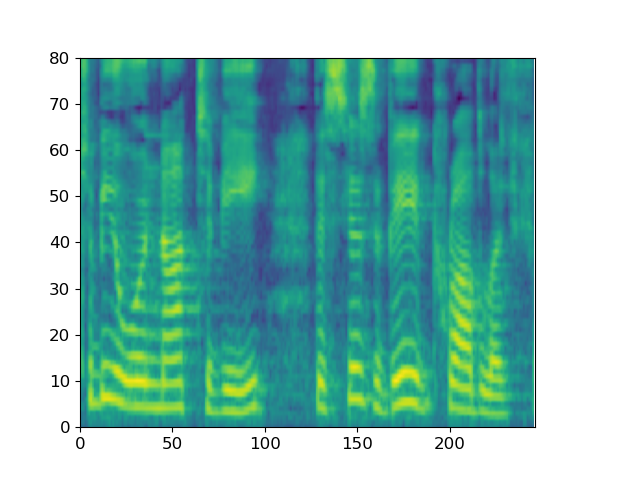
Taking the spectrogram of the sentence LJ032-0167 in LJSpeech as input, ItoWave gradually generates the corresponding waveform from the Gaussian noise signal. The corresponding text is “he concluded, quote, there is no doubt in my mind that these fibers could have come from this shirt.”
Related papers
[1]. Shoule Wu, Ziqiang Shi. ITOWAVE: ITO STOCHASTIC DIFFERENTIAL EQUATION IS ALL YOU NEED FOR WAVE GENERATION. ICASSP 2022.
[2]. Shoule Wu, Ziqiang Shi. ItoTTS and ItoWave: Linear Stochastic Differential Equation Is All You Need For Audio Generation. https://arxiv.org/abs/2105.07583
Contact
Shoule Wu (wu.shoule@protonmail.com), Ziqiang Shi (shiziqiang7@gmail.com, 13621160486)